Why Data Labeling is Essential in Computer Vision [2025]
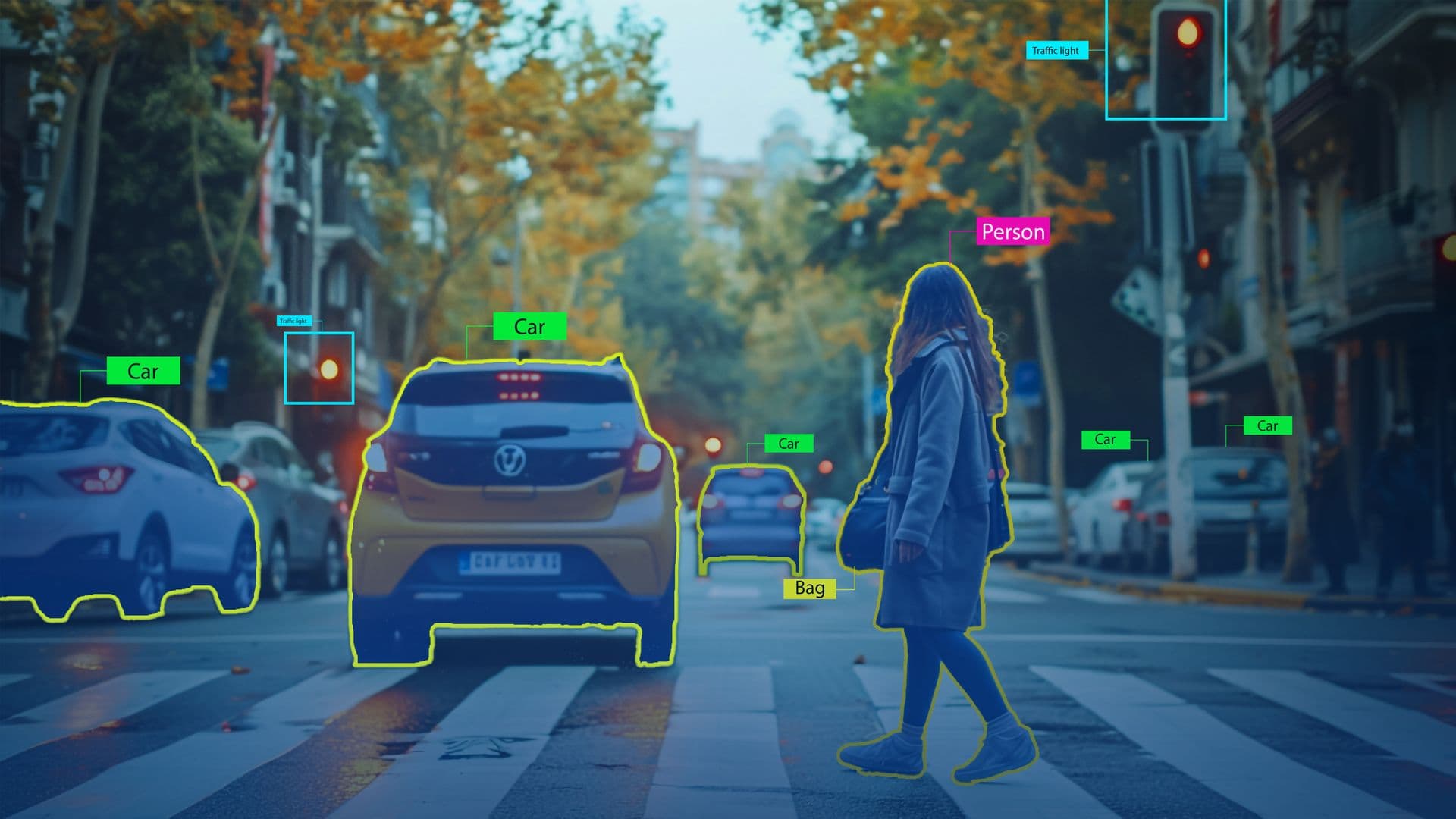
In recent years, there have been amazing advancements in computer vision, the branch of artificial intelligence that allows robots to comprehend and make decisions based on visual information.
Computer vision technologies are revolutionizing businesses all around the world, from facial recognition to driverless cars. However, data labeling—the process of tagging data to train machine learning models—is an important and frequently overlooked component of computer vision. Without well-labeled datasets, computer vision systems would be unable to accurately interpret images, videos, or other visual inputs. In this blog, we’ll explore why data labeling is essential in computer vision, discuss various labeling methods, and highlight how efficient labeling practices can enhance computer vision applications.
Why Data Labeling is Essential in Computer Vision
Data labeling is crucial because it teaches computer vision algorithms to recognize and categorize visual elements within an image. Labeled data is necessary for machine learning models to recognize things, people, or surroundings, understand patterns, and classify information. For example, a model that detects pedestrians in street scenes needs labeled data that differentiates people from vehicles, trees, and other objects. Through labeled examples, these algorithms learn to generalize from the training data, allowing them to perform well on new, unseen data.
Without high-quality labeled data, computer vision models are prone to making errors, misclassifying objects, or misinterpreting scenes. The effectiveness of the model largely depends on the accuracy and consistency of the annotations within the training dataset. For this reason, well-structured and correctly labeled datasets are invaluable for building effective computer vision applications.
Types of Data Labeling Techniques in Computer Vision
- Image Classification: In image classification, each image is assigned a single label or category, helping the model learn to identify different image types. For instance, images might be labeled as “cat” or “dog” for a model distinguishing between animals.
- Object Detection: Object detection is more complex and involves identifying and labeling the position of multiple objects within a single image. Bounding boxes are commonly used to enclose objects, teaching the model to detect and localize specific objects within various contexts.
- Semantic Segmentation: Semantic segmentation is used to assign each pixel in an image a specific class label, enabling precise object boundaries. This technique is valuable in applications such as autonomous driving, where it’s crucial to differentiate roadways from sidewalks, vehicles, and pedestrians at a pixel level.
- Instance Segmentation: Unlike semantic segmentation, which groups similar objects into a single category, instance segmentation assigns unique identifiers to each object instance. For example, in an image with three dogs, each dog would have its bounding area, making this technique essential for applications needing object-level distinction.
- Pose Estimation: Pose estimation involves detecting human or animal key points, such as joints, to analyze movement or posture. This data labeling type is commonly used in fitness apps, sports analytics, and medical imaging, where the goal is to track movement patterns accurately.
The Impact of High-Quality Data Labeling on Model Performance
The accuracy and reliability of a computer vision model depend directly on the quality of labeled data on which it is trained. High-quality labeled data leads to more robust models, lower error rates, and better generalization to new data. Conversely, poor labeling practices can significantly hinder model performance, leading to inaccuracies, poor predictions, and unreliable outcomes. For instance, a model trained on inconsistently labeled images may fail to distinguish between similar objects, diminishing its utility in real-world applications.
To optimize model performance, many organizations use automated tools and machine learning-based labeling solutions. These tools often include validation checks and quality control workflows, ensuring that annotations meet the required standard for training reliable computer vision systems.
How Tools like Labelo Support Efficient Data Labeling
Tools like Labelo streamline the data labeling process, enabling project teams to annotate large datasets accurately and efficiently. Labelo offers a range of labeling functionalities designed to support diverse computer vision tasks, such as object detection, semantic segmentation, and instance segmentation.
By using Labelo’s intuitive platform, teams can:
- Collaborate Seamlessly: Labelo allows multiple annotators to work together in real time, enhancing productivity and consistency in labeling.
- Maintain Quality Standards: Built-in quality control features in Labelo, such as consensus scoring and review workflows, ensure that annotations meet the highest quality standards.
- Automate Parts of the Workflow: By integrating automation with human validation, Labelo helps teams label data faster without sacrificing accuracy, reducing both time and cost.
- Supports Various Data Formats: Labelo supports not only images but also video, audio, and text data, making it a versatile choice for complex machine-learning projects.
Conclusion
Data labeling is an indispensable component of computer vision, shaping the accuracy and effectiveness of machine learning models. High-quality labeled datasets allow computer vision applications to interpret and act on visual information effectively, which is especially critical in fields like healthcare, automotive, and security. Tools like Labelo simplify and enhance the data labeling process, offering the structure, consistency, and efficiency required to build reliable computer vision models. By investing in quality data labeling, companies can unlock the full potential of computer vision, leading to more advanced, accurate, and impactful AI-driven solutions.
Labelo Editorial Team
Jan 24, 2025